Beware Of Anecdotes In The Value-Added Debate
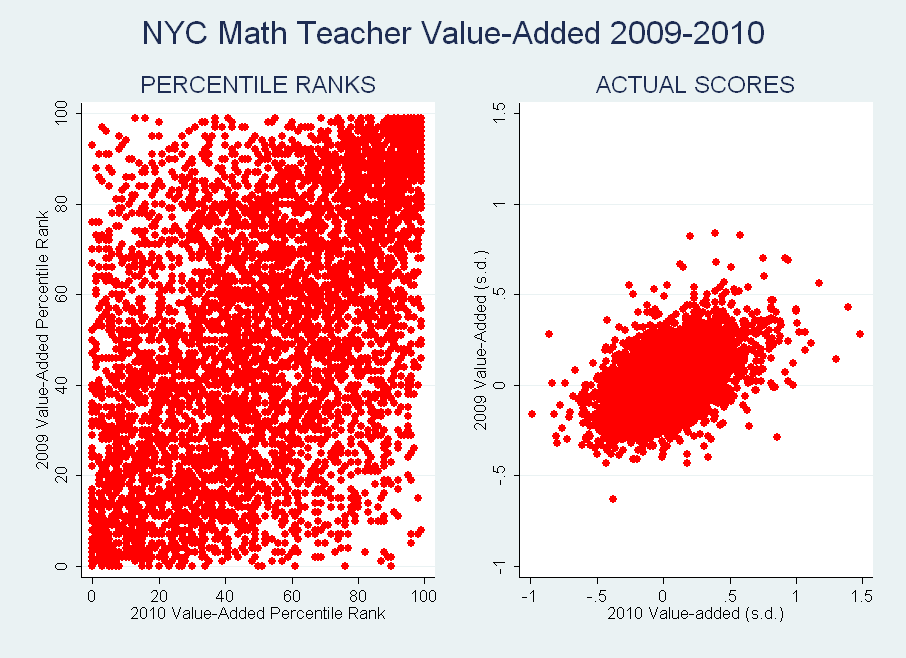
A recent New York Times "teacher diary" presents the compelling account of a New York City teacher whose value-added rating was 6th percentile in 2009 – one of the lowest scores in the city – and 96th percentile the following year, one of the highest. Similar articles - for example, about teachers with errors in their rosters or scores that conflict with their colleagues'/principals' opinions - have been published since the release of the city’s teacher data reports (also see here). These accounts provoke a lot of outrage and disbelief, and that makes sense – they can sound absurd.
Stories like these can be useful as illustrations of larger trends and issues - in this case, of the unfairness of publishing the NYC scores, most of which are based on samples that are too small to provide meaningful information. But, in the debate over using these estimates in actual policy, we need to be careful not to focus too much on anecdotes. For every one NYC teacher whose value-added rank changed over 90 points between 2009 and 2010, there are almost 100 teachers whose ranks were within 10 points (and percentile ranks overstate the actual size of all these differences). Moreover, even if the models yielded perfect measures of test-based teacher performance, there would still be many implausible fluctuations between years - those that are unlikely to be "real" change - due to nothing more than random error.*
{kind=link}
The reliability of value-added estimates, like that of all performance measures (including classroom observations), is an important issue, and is sometimes dismissed by supporters in a cavalier fashion. There are serious concerns here, and no absolute answers. But none of this can be examined or addressed with anecdotes.
In observing the reaction to the value-added stories mentioned above, I was reminded of the New York Times article from a couple of months ago, which featured a District of Columbia Public Schools teacher who received a large bonus for her high evaluation rating. The reporter quoted this teacher saying that the bonus was the reason she stayed in the district. Her story was actually reprinted in other newspapers, and some supporters of merit pay argued that it showed the DC bonus program was serving to retain the district's great teachers.
Yet it was no different from the value-added stories – it was just one instance, which meant virtually nothing on its own. Rather, it had to be placed in the larger context of the research on the relationship between merit pay and teacher retention (we published a post reviewing this evidence, directly in response to the NYT article).
Look, I fully acknowledge the power of “putting a face” on larger problems - the practice is as old as political discourse. These stories have their place (in my view, the truly important argument made by the "6th to 96th" teacher mentioned above was not the size of the change between years, but rather his broadly-applicable point that he had no idea what he had done - e.g., lesson plans, etc. - to bring about the change).
But, as unfortunate as it may be to people who are (understandably) sick of hearing about correlations and error margins, the debate over using value-added in evaluations and other decisions will have to proceed in a manner that keeps anecdotes in proper perspective. It's an obvious point, but the evidence will have to be systematic. Policy discussions, like value-added estimates, require large samples.
- Matt Di Carlo
*****
* Given the small samples, the single-year estimates are pretty much guaranteed to be imprecisely estimated, and thus unstable over time. Putting aside the publication of the NYC data, this instability only matters to the degree that policymakers choose to use value-added in a completely irresponsible fashion - by attaching stakes to estimates without sufficient observations. Unfortunately, that's exactly what's happening in some states and districts. The responsible approach would be, at the very least, to require a minimum sample size and account for error in the estimates. For example, the correlation between the multi-year estimates in 2009 (those based on 2-4 years of prior data) and value-added in 2010 is around 0.50, which is "solidly moderate."
I'd say there is a huge difference between the way that NY Times or the Washington Post uses anecdotes, as opposed to the way the NY Post does, or the way that the NY Daily News reprinted the Washington Post. You can call it anecdotes or we could call it "post-holing." In fact, the failure of academics to ground their theorectical models in reality is huge.
Back in the day when I was in grad school, an econometric model that did not attempt to ground itself in reality better than these models do would be subject to ridicule. I still remember how historians who laughed uncontrollably about econometric models that argued that slavery was profitable and relatively benign and the building of the railroads did not accelerate economic growth and the industrial take-off: a) did not happen, or b) did not cause immense additional suffering as it destroyed the lives of millions. At least they didn't do mass firings of historians based on those primitive models that were later repudiated. (oops I forgot, that take-off model contributed to the Vitenam War ..., but that's ancient history)
In fact, perhaps the worst error by value-added researchers is their fascination with numbers on a macro level, and their obliviousness to the schools that produce those numbers. The ratio of the relative accuracy in the aggregate is fine, but it misses the far more important point that is missed by value-added affectionados. The question is whether value-added will be unfair to teachers who commit to certain types of schools.
My big concern is whether teachers in dysfunctional schools will be able to meet growth targets set, in large part, by growth registered in functional schools. I have yet to see a value-added advocate try to address that point. In fact, I don't believe that many of those theorists even understand the point.
So, in many schools, the error ratio will probably be much worse than 100 to one. But let's take that extremely optimistic ratio and apply it to a dysfunctional inner city school with 100 teachers. That means, on the average,EVERY YEAR teachers will see a colleague get screwed. If you'd like to commit to, say, ten years in one of the toughest jobs around, and that means you'll have a 10% chance of having your career destroyed, by statistical chance, as you also watch your colleagues have their careers destroyed,then the numbers look different. Now, what happens if it turns out that in your tough school you have a 5 to 10 to 15% chance of having your reputation ruined, due to no fault of your own, will you commit to a tough school?