Research On Teacher Evaluation Metrics: The Weaponization Of Correlations
Our guest author today is Cara Jackson, Assistant Director of Research and Evaluation at the Urban Teacher Center.
In recent years, many districts have implemented multiple-measure teacher evaluation systems, partly in response to federal pressure from No Child Left Behind waivers and incentives from the Race to the Top grant program. These systems have not been without controversy, largely owing to the perception – not entirely unfounded - that such systems might be used to penalize teachers. One ongoing controversy in the field of teacher evaluation is whether these measures are sufficiently reliable and valid to be used for high-stakes decisions, such as dismissal or tenure. That is a topic that deserves considerably more attention than a single post; here, I discuss just one of the issues that arises when investigating validity.
The diagram below is a visualization of a multiple-measure evaluation system, one that combines information on teaching practice (e.g. ratings from a classroom observation rubric) with student achievement-based measures (e.g. value-added or student growth percentiles) and student surveys. The system need not be limited to three components; the point is simply that classroom observations are not the sole means of evaluating teachers.
In validating the various components of an evaluation system, researchers often examine their correlation with other components. To the extent that each component is an attempt to capture something about the teacher’s underlying effectiveness, it’s reasonable to expect that different measurements taken of the same teacher will be positively related. For example, we might examine whether ratings from a classroom observation rubric are positively correlated with value-added.
Just how strong that relationship should be is less clear. Recently, I attended a conference session in which one researcher had correlated student surveys and value-added, and another had correlated classroom observation data and student growth percentiles. Both correlations were low, roughly 0.3, though positive and statistically significant. But the researchers’ interpretations were quite different: one described the correlation as sufficient to support inclusion of student surveys in teacher evaluations, while the other argued that student growth percentiles are not appropriate for use in teacher evaluations given the low correlation.

Is it possible for both interpretations to be correct? Maybe, if you expect that: 1) the correlations between student surveys and value-added should be positive but small (as was the case with the results of the first researcher, who interpreted the modest relationship as supporting the use of student surveys); and 2) the correlations between classroom observation data and student growth percentiles should relatively strong (which would be consistent with the second researcher, who found a weak relationship and concluded that growth percentile estimates were not suitable for use). You might visualize that “scenario” as follows:
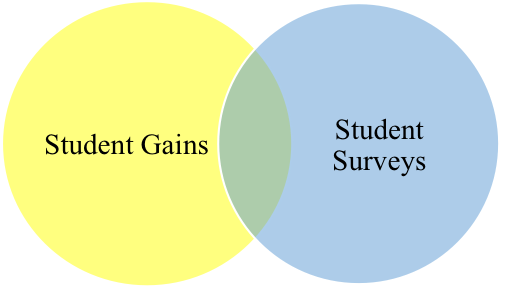
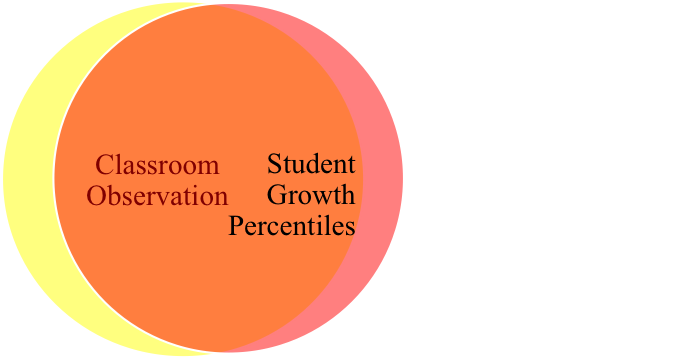
The small green portion of overlap between classroom observations and student surveys represents a small correlation. Perhaps we expect that these two measures are capturing quite different aspects of teacher quality, and thus have only a modest expectation that teachers who do well on one measure may do well on the other. The large orange overlap between classroom observations and student growth percentiles, on the other hand, suggests that we expect these two measures are capturing pretty much the same thing: classroom observations capture the teaching practices that generate student gains.
The classroom observation rubrics I’ve seen attempt to capture a broad set of teaching practices, not all of which necessarily have a strong direct impact student achievement gains; some may address social-emotional climate of the classroom, for example. The inclusion of such practices contributes to the yellow portion of the Venn diagram. The question, then, is whether we could reasonably expect the correlation between ratings based on classroom observation rubrics and student gains to be as large as suggested here. If teacher effectiveness is complex and multifaceted, it would make sense to develop complementary measures: each intended to capture a portion of that complexity, not to replicate one another. If so, then you wouldn’t necessarily expect correlations to be very high.
Another issue with interpreting correlations is that people tend to make assumptions about which measure is accurate and which is flawed. If you view the relationship between student surveys and student gains as too weak, do you blame student surveys or student gains? Both measures are imperfect. Student gains may contain some information about teacher performance, but research indicates they are imprecise and potentially biased. The research base on student surveys is far more nascent, but similarly mixed; student surveys are correlated with student gains, but a recent study of mischievous responders provides some reasons for concern about the quality of information from student surveys.
Similarly, some argue that the correlations between classroom observations and student achievement gains would be stronger if only the raters of classroom observations were less lenient. They assume value-added data are accurate and valid, despite evidence that this information tends to be imprecise and researchers lack consensus as to whether such measures should be used in teacher evaluations (for example, see Corcoran and Goldhaber 2013). Others view measures based on student achievement as being insufficiently valid because these measures do not align strongly enough with classroom observation data. They assume classroom observation data are accurate and valid, though imperfections in classroom observation data have been noted. Rater leniency, rater bias, and the fact that classroom observation ratings tend to be related to the characteristics of the students taught (see Whitehurst et al. 2014) are all concerns. The “noise” in both student-achievement-based measures and classroom observation ratings contributes to the relative modest nature of the correlations.
In reality, every measure is imperfect. Given both the flawed nature of each individual measure, as well as the fact that these measures were intended to capture something that is complex and multifaceted, people should think twice before weaponizing correlations in an effort to support their claims about how good/bad a particular measure is. Lest I sound too fatalistic, I will end on this note: I don’t think any of these measures are devoid of information. I just think we have a better picture of teacher effectiveness if we combine multiple measures and use professional judgment in considering the end result.