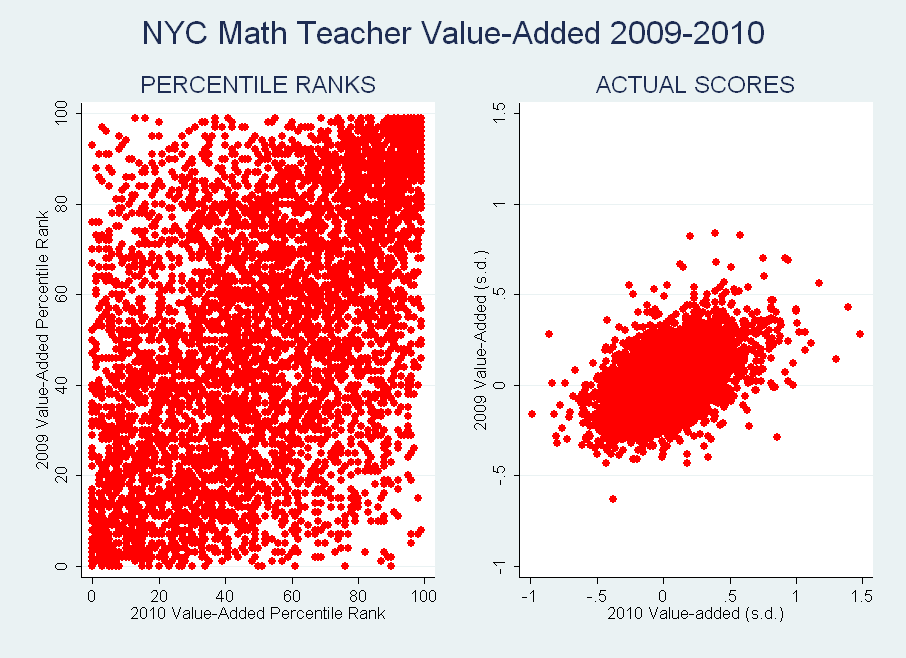
Value-Added, For The Record
People often ask me for my “bottom line” on using value-added (or other growth model) estimates in teacher evaluations. I’ve written on this topic many times, and while I have in fact given my overall opinion a couple of times, I have avoided expressing it in a strong “yes or no” format. There's a reason for this, and I thought maybe I would write a short piece and explain myself.
My first reaction to the queries about where I stand on value-added is a shot of appreciation that people are interested in my views, followed quickly by an acute rush of humility and reticence. I know think tank people aren’t supposed to say things like this, but when it comes to sweeping, big picture conclusions about the design of new evaluations, I’m not sure my personal opinion is particularly important.
Frankly, given the importance of how people on the ground respond to these types of policies, as well as, of course, their knowledge of how schools operate, I would be more interested in the views of experienced, well-informed teachers and administrators than my own. And I am frequently taken aback by the unadulterated certainty I hear coming from advocates and others about this completely untested policy. That’s why I tend to focus on aspects such as design details and explaining the research – these are things I feel qualified to discuss. (I also, by the way, acknowledge that it’s very easy for me to play armchair policy general when it's not my job or working conditions that might be on the line.)
That said, here’s my general viewpoint, in two parts. First, my sense, based on the available evidence, is that value-added should be given a try in new teacher evaluations.
{kind=link}